(Deutsch) Dass eine verlässlich hohe Qualität von Stammdaten jegliche Unternehmensprozesse beflügelt, die auf diese Daten zurückgreifen, wurde bereits in vielen Artikeln ausführlich erörtert.
Aber überall da, wo Stammdaten erfasst werden, passieren auch Fehler. Bleiben diese unerkannt, etwa bei Produktdaten sicherheitsrelevanter Bauteile, kann dies fatale Folgen nach sich ziehen. Eine wirkungsvolle Form der inhaltlichen Qualitätssicherung von Stammdaten ist also obligatorisch.
Beim Landmaschinenhersteller HORSCH im oberpfälzischen Schwandorf sind Frau Hannah Quaas und ihre Kolleg*innen zuständig für die Stammdatenprüfung. Wird dort ein digitaler Zwilling in der Stammdatenprüfung für gut befunden, steht er mit einer verlässlichen Datenqualität in allen nachfolgenden, automatisierten wie teilautomatisierten Prozessen vollumfänglich zur Verfügung.
(Deutsch) Stammdatenprüfung im Freigabeprozess
(Deutsch) Im Rahmen des „Product Lifecycle Management“ hat sich das Freigabewesen als idealer Ort für eine Stammdatenprüfung etabliert. „Ohne Freigabewesen geht es bei uns nicht mehr.“ berichtet Frau Quaas. „Wir prüfen die Produktdaten unserer Maschinenkomponenten auf Richtigkeit und Plausibilität.“ ergänzt sie. Allerdings ist die Fülle an Stammdaten, die für die vollumfängliche Beschreibung der Produkte erforderlich ist, enorm. Neben einfachen Stammdaten wie z.B. der richtigen Benennung sind es z.B. Werkstoffinformationen, Farben, Normen, Herstellungsverfahren, Klassifizierung uvm., die ein Produkt vollständig beschreiben.
(Deutsch) Manuelle Prüfungen sehr zeitaufwändig
(Deutsch) „Wir können in der manuellen Stammdatenprüfung nicht immer alle angegebenen Informationsquellen prüfen. Das ist zum einen nicht immer notwendig und würde zum anderen auch zu viel Kapazität kosten“ erklärt Frau Quaas. Dennoch bleiben die notwendigen, manuellen Prüfungen mitunter sehr zeitaufwändig und sind selber auch wiederum fehleranfällig. Da wird die Stammdatenprüfung auch schon mal zum Flaschenhals im Freigabeprozess.
Zudem wird seitens der Stammdatenprüfung explizit nicht auf Vollständigkeit der Konstruktion an sich geprüft. Solche Fehlerquellen werden bereits im Vorfeld im Entwicklungsprozess ausgeschlossen und landen erst gar nicht beim Stammdatenprüfer.
Es geht mehr um die inhaltliche Plausibilität der Produktdaten. Während eine einzelne Eigenschaft eines Produktes für sich genommen richtig sein kann, können unter Einbeziehung aller Informationen zu dem Datensatz Zweifel an der Richtigkeit der Angaben entstehen.
Auffällig hierbei war, dass auf viele, ähnliche Prüfungen intuitiv gleiche Prüfschritte erfolgten. Für die Prüfungen waren zu diesem Zeitpunkt bereits zwei Mitarbeiter*innen voll beschäftigt. So wurde im Juni 2020 im Rahmen eines Workshops die Arbeit der Stammdatenprüfung im Detail analysiert mit dem Ziel, entsprechende Prüfungsregeln herauszuarbeiten und festzulegen.
Hierbei stellte sich heraus, dass für bestimmte Teilegruppen bestimmte Regeln angewendet werden können, mit denen die Qualität der Produktdaten sehr genau bestimmt werden kann.
Bereits während des PDM-Einführungsprojekts hatte Frau Quaas im Rahmen Ihrer Masterarbeit mittels Clusteranalyse herausgefunden, welche Artikel-Eigenschaften für das Finden von Ähnlichkeiten im HORSCH-Teilespektrum überhaupt relevant sind. Als Clusteranalyse wird ein Gruppenbildungsverfahren aus der Statistik bezeichnet, das zur Entdeckung von Ähnlichkeiten innerhalb größerer Datenbestände genutzt wird. Diese Erfahrungen waren dann auch bei der Regelfindung für eine spätere Automatisierung von großem Nutzen.
Mit diesem Wissen war die Erkenntnis gereift, Teile der Stammdatenprüfungen automatisieren zu können. Das Ziel war: Dort, wo die Teilegruppe es erlaubt, soll die Stammdatenprüfung vollautomatisch erfolgen. Nur wenn der Algorithmus Auffälligkeiten entdeckt, sollen die Teile zur manuellen Stammdatenprüfung weitergeleitet werden. So können neben einer spürbaren Entlastung der Prüfer auch insgesamt die Durchlaufzeiten verbessert werden, da eine automatisierte Prüfung wesentlich schneller abläuft.
(Deutsch) Gruppenbildungsverfahren aus der Statistik hilft bei der Datenanalyse
(Deutsch) Aber wie funktioniert die Prüfung konkret?
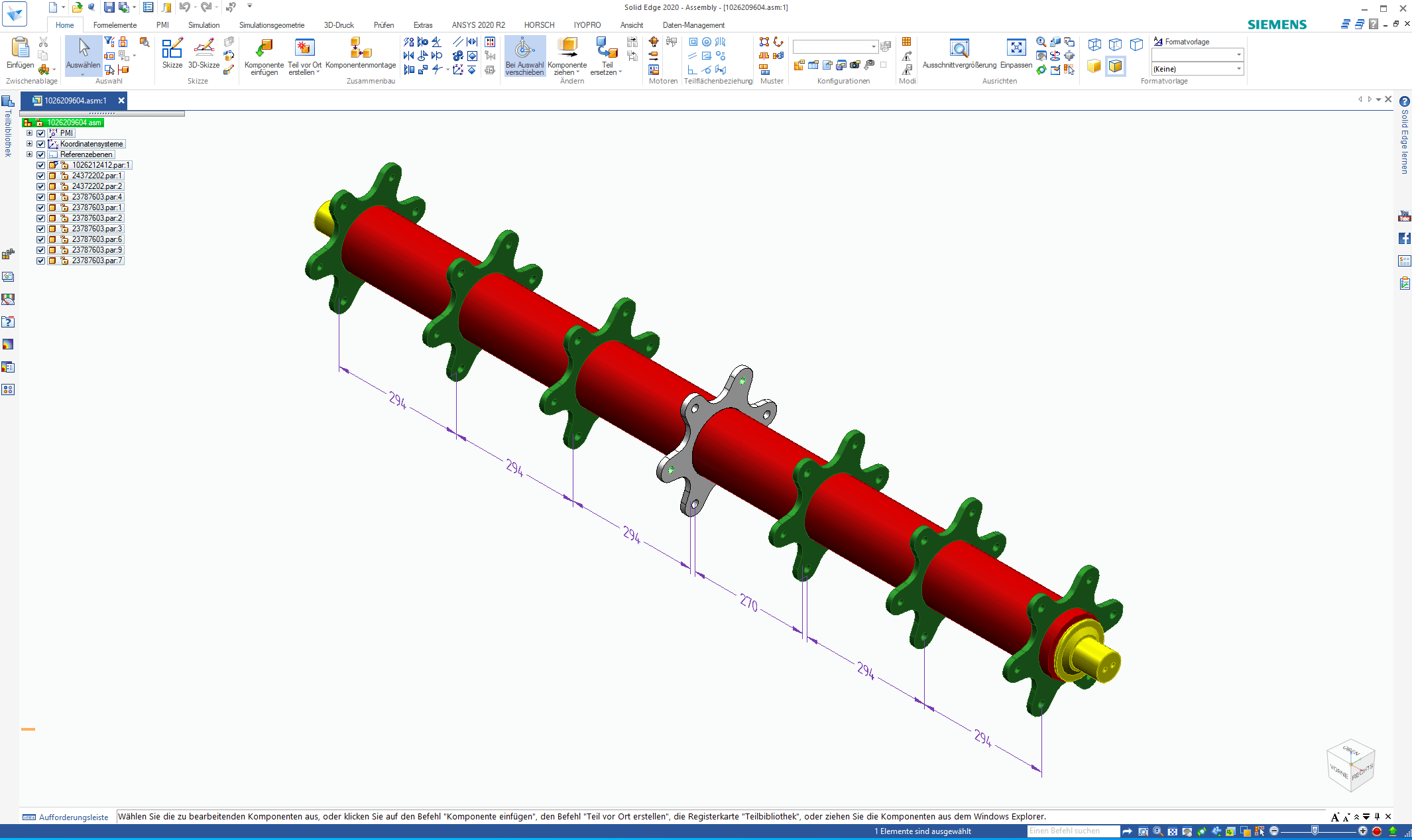
Dies soll im Folgenden am Beispiel eines Packerrohrs veranschaulicht werden:
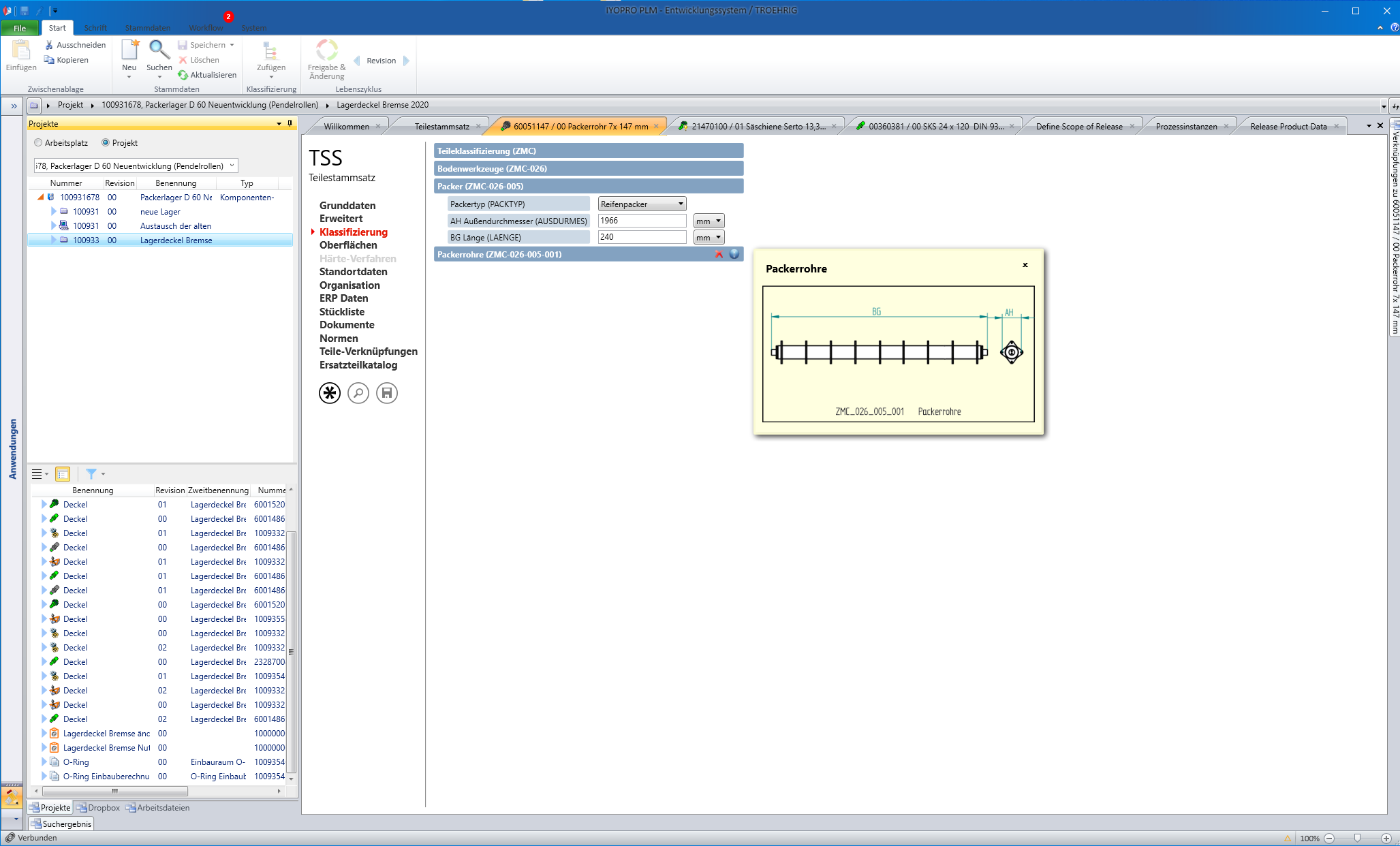
Wenn die Konstruierenden eine Entwicklung als „Packerrohr“ klassifizieren, werden Merkmale aktiviert wie etwa Länge und Außendurchmesser, die vom Konstrukteur anzugeben sind.
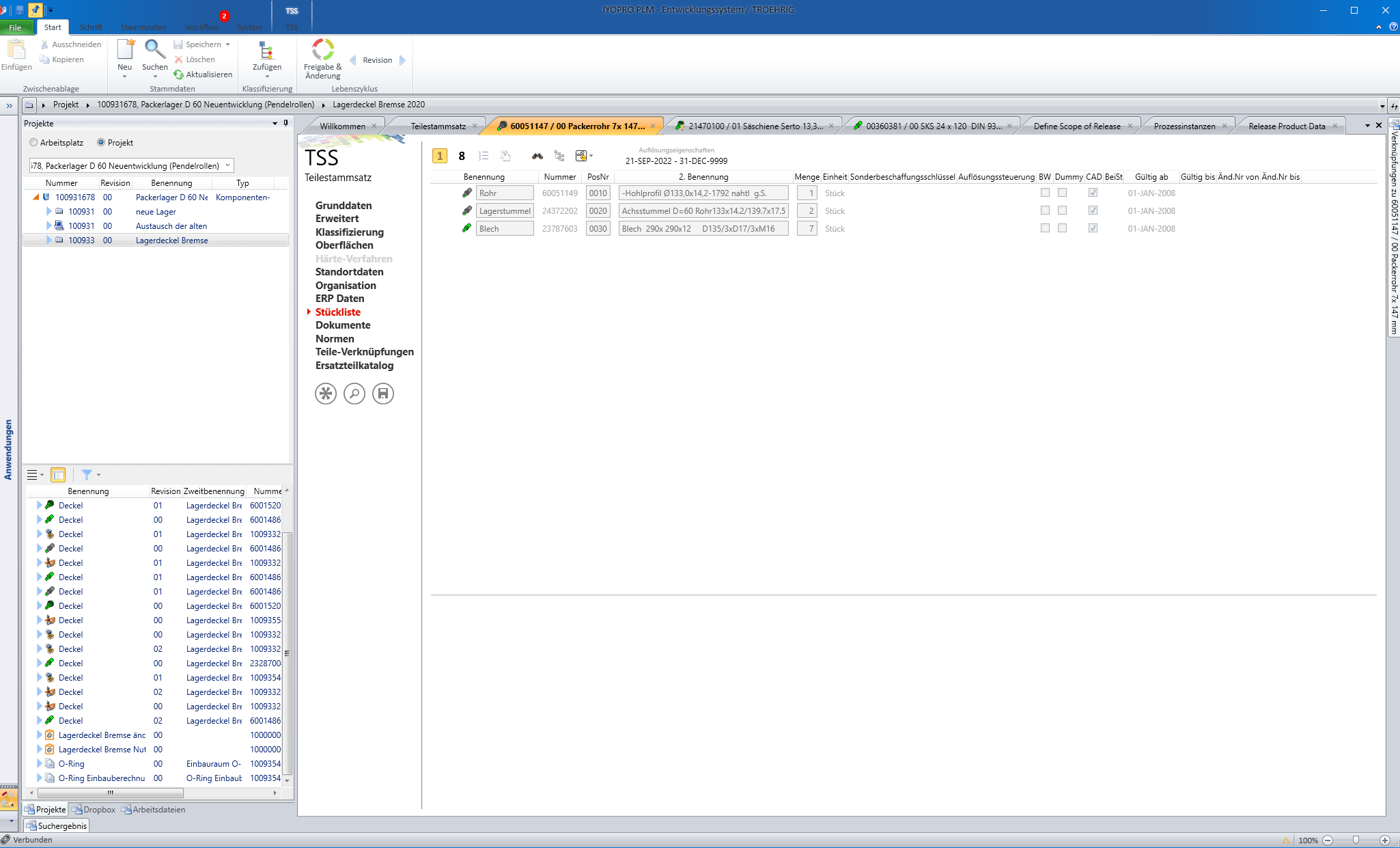
Im Rahmen des digitalen Freigabeprozesses wird nun das Regelwerk für Packerrohre herangezogen und die dort hinterlegten Prüfungsschritte abgearbeitet. Dabei hat das Regelwerk Zugriff auf sämtliche Eigenschaften des Artikels, dessen Stückliste, die CAD-Modelle und Zeichnungen sowie sonstige beschreibende Dokumente. Auch lassen sich die Regeln über die Baugruppen-Hierarchieebenen hinweg verschachteln. So muss ein Packerrohr in dessen Produktstruktur etwa immer aus einem Hohlprofilabschnitt (rund oder eckig), mindestens einem Blech und zwei Achsstummeln bestehen.
(Deutsch) Metadaten als Schlüssel
(Deutsch) Um ein Blech in der Produktstruktur wieder als Blech zu identifizieren muss natürlich auch dieses korrekt klassifiziert sein. Außerdem werden z.B. die Modellgeometrien mit Maßen in der Klassifizierung verglichen und Volumina in Verbindung mit Werkstoffeigenschaften für die Gewichtsbestimmung herangezogen.
Im Ergebnis bestimmt das Regelwerk die Wahrscheinlichkeit, wie plausibel die Produktdaten ineinandergreifen sowie Hinweise, welche Regeln ggf. verletzt oder auffälig waren.
„Das Regelwerk sorgt jetzt dafür, dass wir aus dem gesamten Entwicklungsumfang von den automatisierten Klassen nur noch die aussortierten Fälle zur manuellen Prüfung erhalten, bei denen Zweifel an der Plausibilität festgestellt wurden“ erklärt Frau Quaas.
Das Regelwerk selber mit seinen Entscheidungstabellen wird hiebei durch HORSCH innerhalb von IYOPRO PLM eigenständig gepflegt. „Zu Beginn einer neu unterstützten Teilegruppe machen wir immer noch stichprobenartige Prüfungen. Sind die Regeln dann allerdings erprobt, können wir uns auch zu 100% darauf verlassen“ ergänzt Frau Quaas.
 (Deutsch) Hannah Quaas
(Deutsch) Hannah Quaas
„Wichtig ist mir, dass bei allem Fortschritt die Menschen hinter den Bildschirmen nicht vergessen werden.“
(Deutsch) Bei etwa 100 Freigabeprozessen am Tag und einer automatischen Abdeckung von derzeit 10-15% des Teilespektrums belaufen sich Einsparungen alleine in der Stammdatenprüfung derzeit auf etwa 3 Stunden täglich. „Machbar sind Stand heute 50-60% des verwendeten Teilespektrums“ führt Frau Quaas im Hinblick auf die Menge an homogenen Teileklassen aus. Hinzu kommen die Einsparungen in der Durchlaufzeit sowie die Tatsache, dass die automatischen Prüfungen mit konstanter Qualität abgearbeitet werden. Auch imperiale Teile, etwa Halbzeuge, sollen in Zukunft automatisch geprüft werden. Gerade durch den weltweiten Einsatz und der damit verbundenen Zeitverschiebung kann die automatische Prüfung Durchlaufzeiten nochmals erheblich senken.
„Es hat sich auf jeden Fall gelohnt! Wenn ich etwas anders machen würde dann nur, dass wir früher hätten damit anfangen sollen“ zieht Frau Quaas Bilanz. „Auch die Zusammenarbeit mit intellivate haben wir als sehr angenehm empfunden. Die Beratungen und gemeinsam geführten Workshops waren stets auf Augenhöhe und wir haben immer einen Lösungsweg gefunden. Vielen Dank dafür!“